在上一個章節,筆者介紹了一些隨機分派相關的軼事,與執行隨機分派的主要設計方式,以及幾種常見的型態與執行的概略流程圖。而在本章節,筆者將介紹以隨機分派為核心的臨床試驗研究,又稱為Randomized control trial (簡稱RCT),其基本的研究執行流程如下圖:
 |
Figure 1. Structure of randomized control trial |
一個RCT的執行絕非一人之力所及,一個成功的RCT也必須考量諸多事宜,研究成員、受試者、分析人員、測量工具、分析方法、研究設計的流程、時間、資源的限度、甚至是試驗的藥劑於上市後的追蹤與調查等,任何一個環節出現失誤或隱瞞,都可能會造成RCT的結果產生誤差,最後影響的就可能是數千人甚至是上萬人受到影響。
因此在本章節,筆者將會進一步介紹臨床試驗研究的幾種重要的考量。這些考量關係著試驗研究是否符合人道與醫療道德標準、是否是合法、合理的研究、是否是有效的研究,其研究結果是否可信、其推論是否可以應用於臨床醫療的實務面等。
Inclusion and exclusion criteria
一個RCT在抽樣的過程,可以利用一些適當的篩選(inclusion and exclusion)標準來避免樣本內個體間的特徵分佈失衡,並規範適合的受試者才得以進入RCT。此能保護隨機分派能有效地分派具有同質性的treatment group和control group。篩選條件有五點方向可供參考:
- 樣本個體的身體與罹病狀況是否與研究目標所感興趣的outcome有共病現象。
- 族群中任何疾病的從生理出現反應到出現症狀,皆需要足夠的時間去發展,而一個RCT也會針對這個特性設計合理的追蹤期(follow-up period)。若樣本所選擇的受試者,其存活的時間很明顯可能比追蹤期更短,或者根本沒有足夠的存活時間讓受試者出現症狀,則應該斟酌予以排除。
- 若受試者對於介入措施會引起任何不良反應,則此受試者不能參與RCT。
- 若受試者在研究收集樣本的期間明確表達拒絕參與RCT,則必須尊重其意願而予以排除在RCT之外。若受試者在研究執行的任何時間點決定退出,也同樣必須予以排除。
- 若受試者願意接受RCT研究,卻不願配合隨機分派的結果接受treatment group或control group的介入措施,甚至接受不在研究控制的介入措施,則為了研究效度的考量,可以斟酌予以排除。
上述的五點均為了保持研究的有效性,但研究者也必須留意,過度的篩選很有可能會導致RCT研究的結果無法外推至目標族群(target population),令研究成果無法有效應用於目標族群身上。也因此RCT的研究成果之推論與應用必須相對地保守,至於補救研究外推性(generalizability)的方法,研究者可以增加有效的樣本數,但成本耗費極高。
Equipoise
若研究者明確知道施用於treatment group的介入措施比control group更具備療效,則這樣的RCT就違反了研究倫理。因此RCT研究只能執行那些不明確或需要更強證據來證實施用於treatment group的介入措施"可能"有效於control group。
Intervention of treatment and control groups
介入措施,不論是treatment group或是control groups,皆需要進行審慎評估,並考量這些介入措施是否符合研究所需或實務層面的許可程度。以treatment group來說,介入措施往往是研究目的所預期的具有更好的效果,因此這些介入措施往往需要符合幾項考量:
- 需要臨床試驗評估的介入措施是否能在試驗結束後,真正實踐於臨床醫療行為上,或者是足以讓醫師、護理人員所接受?若不行,則進行此介入措施的試驗研究,是否太過理想性、太簡化而無法應用落實?
- 是否真的能符合出實務上的需求與必要性?
- 是否真的與試驗所關心的outcome事件有關係?這種相關性是否是巧合?
在此需要特別說明,介入措施並非只能進行一種,兩種以上的介入措施組合,也是臨床試驗常見的手法。因此做為比較的control group在選擇介入措施時,也能夠由treatment group的介入措施組合中,挑選適合的部分措施來施用。例如在牙科治療相關的臨床試驗當中,在treatment group有包含每月潔牙訓練與定期洗牙等數種措施,而control group則可能僅包含每月潔牙訓練與定期洗牙兩種。
另外,若臨床試驗的目的是希望能夠找出更安全、更具效果的介入措施,來取代當前的常規臨床行為或治療,則control group則可以常規療法來做為比較。
Blinding
一項臨床試驗往往需要團隊分工合作才能順利,而這些分工就包含一開始的研究預前規劃、設計、選樣與隨機分派,臨床醫師與受試者的接觸以進行檢查、診斷、複檢、以及給予介入措施,而最後則是結果評估。有些試驗研究的設計、隨機分派與評估是由同樣一組研究人員處理,但也可以是不同的人員處理。而試驗研究的成敗往往會取決於是否能夠保持隨機分派的結果,而盲處理(blinding)就是一種保護隨機分派的方法,也是一種避免過多人為(主觀)干預介入影響研究設計的方法。
因為試驗研究皆是以人為主的研究,而人類的主觀態度往往會影響其判斷與決策,不論是醫師、受試者、乃至於評估人員皆是。舉例來說,若受試者知道自己是被分在哪一組,則當受試者身體出現任何反應時,有可能會因此自行更換介入措施或甚至是退出研究。若醫師知道受試者在隨機分派後的組別,則對於treatment group的受試者,醫師就會預期在受試者身上觀察到研究目的所關心的outcome事件,因此檢查時比較容易會忽略與研究目的無關的outcome事件。對於評估人員而言,若知道評估時隨機分派的組別,有可能會因此偏袒於那些與研究目的所關心的outcome事件,導致研究結果失去客觀立場。
因此根據上述的三個環節的研究參與者,盲處理的設計可分為以下幾種:
- 單盲(Single blinding):對上述三項的任何一項參與者進行盲處理,令其未知隨機分派的結果。常見的為針對醫師,或者是受試者的盲處理。
- 雙盲(Double blinding):對上述三項的任何兩項參與者進行盲處理,令其未知隨機分派的結果。常見的為針對醫師與受試者的盲處理。
- 三盲(Triple blinding):對上述三項的參與者進行盲處理,令其未知隨機分派的結果。
Outcome assessment
在RCT研究執行的後端,就是outcome的評估。其outcome可以選擇以疾病來評估、以存活的狀態來評估、以預後(prognosis)的狀態來評估、以生理指標來評估(例如CD4數值、糖化血色素HbA1c數值、體脂肪、膽固醇等)、甚至以生理功能的狀態來評估(例如肌耐力、骨密度、BMI等)。而這些事件可以選擇以單一的事件來評估,也可以選擇以多重(複合)的事件來評估,而後者常稱為composite outcome。
在其多重組成之中,各項事件經常互有關聯。而使用多重組成的事件之優點,則是可令RCT的outcome更容易被研究觀察到。反之,其缺點則是難以釐清各事件發生與介入措施之間的關係。若要避免造成過於含糊不清的研究結果,研究者可以選擇採用單一的事件來作為評估,但其缺點就是很容易會觀察不到足夠的發生數,來推論介入措施與控制組之間的差異性。也因此,研究者往往需要在研究執行初期,以先驗知識來推測研究所關心的事件是否是容易發生的,若很明顯是罕見的,則建議採用composite outcome方式,集合適當的數種事件來做為結果評估。
而RCT執行過程,受試者很可能會追蹤到follow-up period結束後才停止試驗,也可能是失去聯絡而停止研究追蹤,也可能是因為其他因素而自行決定退出研究而終止試驗,也有可能是意外事故死亡而退出試驗,除了上述的幾項因素,受試者通常會在達到研究所設定的終點(endpoint)而結束試驗,而這個終點若是研究目的需要的,或者是研究議題至關重要的事件結果(outcome),則稱為primary endpoint。除此之外,若這個終點是與研究目的相關的,或者是與primary endpoint互有關聯的事件,則往往設定為secondary endpoint。
例如一項針對罹患過腦血管疾病的更年期婦女的試驗研究,該研究目的希望了解這群更年期婦女使用荷爾蒙替代療法是否有助於腦血管疾病的預後。因此該研究將primary endpoint設定為死亡事件或者是非致命性的腦中風事件。而secondary endpoint則設定為短暫性的腦中風事件(俗稱的小中風)與非致命性的心肌梗塞事件。
另外,試驗的終點也可能是為了避免受試者因為試驗進行而過度身體惡化的終止點。有鑑於此,試驗研究往往都會定期接受評估,判斷試驗是否對於受試者造成過度影響,是否能夠持續進行下去,若判斷此試驗已經對受試者造成惡化或不良反應過多,則將會立即終止試驗,並停止受試者使用的介入措施。
Intention-to-treat and per-protocol analysis
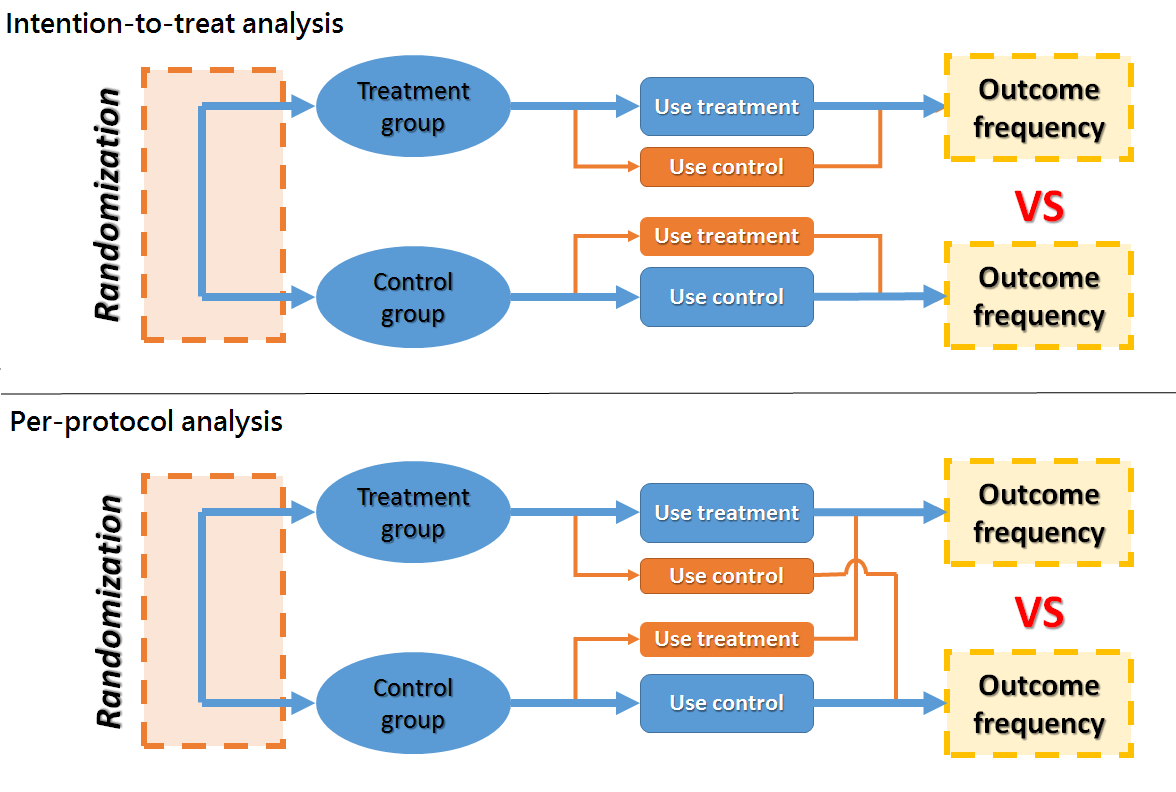 |
| Figure 2. Structure of an intention-to-treat and per-protocol analysis |
Intention-to-treat (ITT) analysis的做法和精神是保持隨機分派(Randomization)的完整性。因此不論RCT的過程中受試者實際上所使用的介入措施是否同於隨機分派後所指定的介入措施,在分析時,皆一律採用隨機分派的分組來做比較。其缺點是容易造成結果的低估,因為受試者在實際上並不會全都乖乖地接受隨機分派所指定的介入措施,而可能會在分派後互換介入措施。為了降低受試者在隨機分派後使用指定介入措施的不同意程度,研究者可以在研究執行前先行篩選,將遵守意願較低的受試者先排除,或者是在隨機分派時請求受試者同意使用指定的介入措施,而不會隨意更動。或者是進行衛生教育,先讓受試者了解將使用的介入措施可能與什麼藥物治療會造成不良反應的交互作用。
反之,若分析時採用的treatment group與control group比較,是遵從受試者實際上所使用的情形而非隨機分派的結果。則此做法稱為per-protocol analysis。然而這樣的分析策略雖然可以避免研究結果低估,但這種形同破壞隨機分派的分析策略,卻容易產生不必要的干擾因子而導致研究結果的有效性降低。
The aim of trials反之,若分析時採用的treatment group與control group比較,是遵從受試者實際上所使用的情形而非隨機分派的結果。則此做法稱為per-protocol analysis。然而這樣的分析策略雖然可以避免研究結果低估,但這種形同破壞隨機分派的分析策略,卻容易產生不必要的干擾因子而導致研究結果的有效性降低。
如前述一直所提到的,RCT研究流程在於比較treatment group和control group兩組在各自實施介入措施後,兩組群體的反應是否有差異。而談到比較兩組或多組差異的問題,我們不得不在此提到統計檢定(statistical test)的概念。
筆者曾經在"流行病學的因果推論"那一章節提到Karl Popper爵士提出的反證法(Falsifiability),反證法的概念就是去不斷檢驗我們想證明的某種假說,透過不斷地去推翻此假說的對立面來讓獲得逼近真相的方法。換言之,真相無法證明,但可以逼近它。而統計檢定也承襲了這樣的概念,透過研究者所設立的研究假設,設計研究流程去創造一個情境,並在情境內建置了某些條件可以去推翻此假設的對立面,然後透過統計檢定的方法來嘗試了解,我們推翻此假設的對立面是否足以信賴。因此同樣目的之研究可以容許不同時空下重複去設計執行,因為研究永遠只能推翻假設的對立面,而無法論證假設是否為真。
現在讓我們來考慮試驗研究的精神,筆者在前一章節曾經提到,試驗研究必須符合醫學倫理的規範,也就是不得對受試者施以有危害性的處置,或在研究過程讓受試者受到危害。在這樣的大前提下,流行病學者對於試驗研究的期望,就不外乎是拿來處理治療方法、療效、保護性、協助存活、醫療技術等具備有益性質的研究,而醫學研究對於何謂有益,以及如何在試驗研究中來證實有益這件事,就採取了上述統計檢定的概念,也就是以反證法來推論何謂有益。由此可知,醫學研究無法證明有益性質為真相,但能透過不斷推翻無益或有害的對立面來讓此有益的現象越來越逼近真相。
隨著醫學發展的多樣性,試驗研究的用途變得十分廣泛,針對有益性質這件事本身也可以有更多的立意。為了方便說明,筆者會以藥物來舉例,當我們希望執行一項試驗研究來證明某樣新藥的療效比特定藥物更具好,並依照生物醫學背景知識來設定某個程度以上的療效差異,並要求新藥的療效要超過此程度才能稱為夠好。而這樣試驗研究目的,在臨床流行病學裡稱為Superiority trials。
另外,試驗研究在某些需求下,也會執行研究去證明兩種藥物療效沒有差異,但在統計檢定的方法,證明兩種藥物療效是完全相等的假設,是無法執行的,因此在臨床試驗中經常會以equivalent來取代equal的概念來處理,也就是容許兩種藥物療效的比較之假設可以有一些差異,換言之,就是設定某個差異範圍(可以稍微好或稍微差一點),並假設兩種藥物療效比較只要介於此範圍內,就稱兩種藥物沒有太大差異,也因此,這樣的試驗研究也被稱為Equivalence trials。
還有一種情境常用於新藥與常規藥物的比較,此種試驗研究需要證明新藥沒有比常規藥物還差,就算新藥的療效不及常規藥物,但只要能證明新藥的療效沒有差很多,就可以說明新藥有做為另一種治療選擇的價值。以實務上來說,這種試驗是十分重要的一項,特別是某些患者因為生理條件上的問題而無法適應常規藥物的作用(例如藥物過敏等),因此亟需要另一種可以針對此疾病作用的藥物來治療,而這類型的試驗就是這些患者在治療上的救命方法。因此這類型的試驗也稱為Non-inferiority trials。
Summary
臨床試驗(clinical trial),作為流行病學研究中的試驗研究之最主要的一項研究型態,已是現今醫學發展不可或缺的一環,也是許多患者的希望,透過臨床試驗所發展的新藥,許多已是現今治療傳染病、愛滋病、癌症、慢性病,甚至是罕見疾病的第一線藥物。在本章節介紹了一些常見的臨床試驗研究的考量,許多考量看似繁瑣、保守、綁手綁腳,甚至會因此徒增研究經費、花費數倍的研究時程去規劃研議,目的就是為了符合醫學倫理的規範。然而這些都是必要的,即使有人完全符合醫學倫理的規範,也只是符合了最基本的要求。
臨床試驗研究的成功與失敗,受到傷害的是人,受惠的也是人,正因為如此,作為流行病學家才更應該謹慎細心地去看待,真正的從心去尊重這些人,感謝他們對於研究的付出,而不是坐等研究數據的產生。我們需要時時刻刻知道,每一筆數據都是一個真實的人,每一筆發生數都代表著真實的人正受到疾病的侵襲,每一筆死亡數代表的不單純只是受試者符合醫學上定義的失去生命徵狀,更多的是這名受試者身邊的家人、朋友的惋惜。若是為了讓試驗藥物能順利上市而刻意忽視受試者身上的不良反應,或者是修改不良率的數據,引用錯誤的方法去估算較漂亮的結果,導致上市後造成數千人以上的傷害,這種行為無異於過失致死、過失傷害。
然而醫學發展至此,仍時有所聞一些對於受試者造成危害的不道德事件,或者是爭議事件頻傳。這也是為何至今仍定期會修訂赫爾辛基宣言的原因,並非是不信任醫師或研究者,而是給予未來的研究一個指引的方向,引導這些研究避免去造成對人的危害。
awesome!
回覆刪除你好,讀了你博客內有關流行病學的內容,很好,很詳細及精彩~
回覆刪除望你能繼續與我們分享流行病學呢...
我也將你的博客分享到我的博客之中呵~(mansichan.blogspot.com)
Great!
刪除很多內容的架構與脈絡其實都已經預備好,只是尚未有時間去寫,希望未來能有機會將那些觀念寫出來。
深入淺出的說明,很棒
回覆刪除